


Konuşmacı tanıma süreçlerindeki doğruluk adli bilişim alanında önemli bir yere sahiptir. Bu çalışmada, konuşma sesi kayıtlarında gerçek zamanlı olarak iyileştirilmesi ile söz konusu doğruluğun artırılması hedeflenmiştir. Bu kapsamda iki tür ses iyileştirme katmanı gerçeklenmiştir. İlk katmanda sesteki gürültülerin DSP (Sayısal Sinyal İşleme) teknikleri ve FFT (Hızlı Fourier Dönüşümü) kullanılarak zaman – frekans alanında filtrelenmesi söz konusudur. Sonraki katmanda konuşma sesinin ANN (Yapay Sinir Ağları) kullanılarak diğer çevresel seslerden ayrıştırılması sağlanmıştır. Bu çalışmada, C++ programlama dili ve nesne yönelimli programlama yaklaşımı ile ilgili yazılım gerçeklenmiştir. Sonuçta söz konusu yazılımın örnek ses kayıtları üzerinde yüksek doğruluk ile iyileştirme sağladığı görülmüştür. Sonraki süreçte bu filtrenin kullanıldığı MFCC (Mel Frekansı Kepstrum Katsayıları) ve GMM (Gauss Karışım Modeli) tabanlı konuşmacı tanıma yazılımı gerçeklenmiştir. Bu aşamada yazılım VoxCeleb isimli büyük ölçekli ses kayıtları veri kümesi ile test edilmiştir. Elde edilen sonuçlarda gürültü içeren ses kayıtları için konuşma tanımada doğruluk artışı olduğu görülmüştür. Ayrıca temiz ses kayıtları için herhangi bir kayıp olmadığı anlaşılmıştır.
Accuracy in speaker recognition processes is important in computer forensics. In the aim of this study is to increase accuracy by improving speech in real time. In this context, two types of sound improvement layers have been implemented. In the first layer, the noise in the sound is filtered in the time-frequency domain using DSP (Digital Signal Processing) techniques and FFT (Fast Fourier Transform). In the next layer, the speech sound was separated from other environmental sounds by using ANN (Artificial Neural Networks). In this study, the software was implemented with C++ programming language and OOP (Object Oriented Programming) approach. As a result, it was seen that this software provides enhancing with high accuracy on sample sound recordings. In the next process, MFCC (Mel Frequency Cepstral Coefficients) and GMM (Gaussian Mixture Model) based speaker recognition software using this filter was implemented. At this stage, the software was tested with VoxCeleb large-scale dataset that contains speech recordings. The results show that there is an increase in the accuracy of speech recognition for sound recordings containing noise. It has also been found that there is no loss for clear sound recordings.
İlgili İçerikler
Key
Köker Belgeindir 1.3
Kabul
Known
Know
Sosyal Paylaşım
 Facebook'ta Paylaş
Facebook'ta Paylaş  LinkedIn'de Paylaş
LinkedIn'de Paylaş  Twitter'da Paylaş
Twitter'da Paylaş Resimler

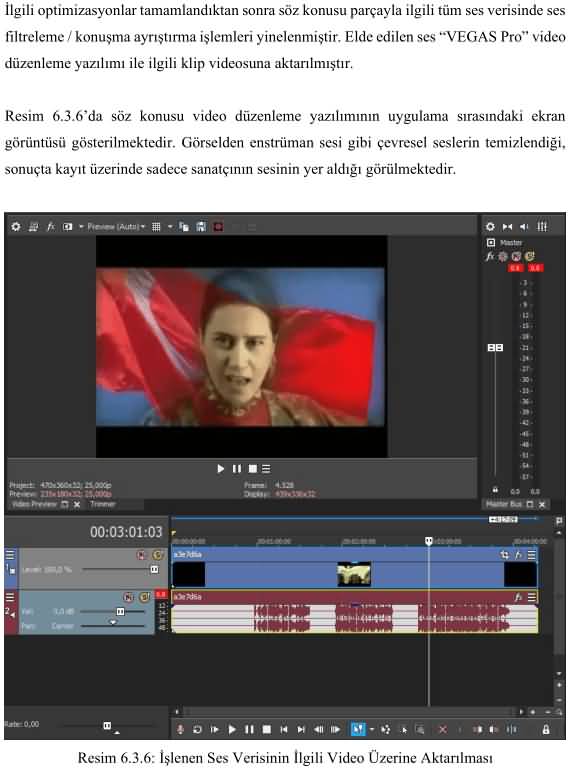
Öne Çıkanlar
 Köker Belgeindir 1.3
Köker Belgeindir 1.3  Köker YazıcıTamir 1.5
Köker YazıcıTamir 1.5  Köker Zamanla! 1.0
Köker Zamanla! 1.0  Köker Bilet Otomasyonu 1.0 (Java)
Köker Bilet Otomasyonu 1.0 (Java)  Köker Öğrenci Otomasyonu 1.0 (Java)
Köker Öğrenci Otomasyonu 1.0 (Java)  Köker Hastane Otomasyonu 1.0 (C)
Köker Hastane Otomasyonu 1.0 (C)  Köker PortLogger 1.0
Köker PortLogger 1.0  Köker Öğrenci Otomasyonu 1.0 (C++)
Köker Öğrenci Otomasyonu 1.0 (C++)  Köker GizliBilgi 1.0
Köker GizliBilgi 1.0  Köker SigmaCebir 1.0
Köker SigmaCebir 1.0  Mini İnsansız Hava Aracı Yazılımı (Danışman: Doç. Dr. Atilla Ergüzen)
Mini İnsansız Hava Aracı Yazılımı (Danışman: Doç. Dr. Atilla Ergüzen)  Yapay Zeka Kuramdan Uygulamaya (Kitap Bölümü)
Yapay Zeka Kuramdan Uygulamaya (Kitap Bölümü)  Konuşma Sesi Ayrıştırma Sistemi (Danışman: Doç. Dr. Güray Sonugür)
Konuşma Sesi Ayrıştırma Sistemi (Danışman: Doç. Dr. Güray Sonugür)  Nesnelerin İnterneti Kuramdan Uygulamaya (Kitap Bölümü)
Nesnelerin İnterneti Kuramdan Uygulamaya (Kitap Bölümü)  Konuşmacı Tanıma Sistemi (Danışman: Doç. Dr. Nursel Yalçın)
Konuşmacı Tanıma Sistemi (Danışman: Doç. Dr. Nursel Yalçın)  Baykar: Stajyer Bilgisayar Mühendisi
Baykar: Stajyer Bilgisayar Mühendisi
Son Görüntülenenler
 Helpful
Helpful